Seamless yield-and-resume
for accelerator workloads
Stop paying for idle GPUs. Automatically yield resources when inactive, resume instantly when needed.
Our Mission
Our mission is to unlock trapped accelerator capacity by replacing static accelerator reservations with yield-and-resume.
Today, a big chunk of accelerator capacity sits reserved but idle — held by researchers in meetings, agents waiting on input, or workloads that aren’t actively using the hardware. This trapped capacity creates false scarcity and drives wasteful over-provisioning. Affinode is the liquidity layer for modern compute, enabling workloads to automatically yield accelerators when idle and seamlessly resume without losing state. By coupling allocation strictly to real activity, organizations can serve more users on fewer accelerators, shifting from peak-provisioned clusters to truly demand-driven efficiency.
Key Features
Release When Idle
Workloads release hardware when idle, eliminating wasted capacity and false scarcity.
Seamless Resume
Resume workloads without state loss. Your work continues exactly where it left off, ensuring zero disruption.
Demand-Driven
Move away from wasteful peak-provisioning to true, demand-driven efficiency. Serve more users on fewer accelerators.
Decoupled Allocation
Decouple allocation from utilization. Resources are allocated dynamically based on actual need, not static reservations.
Cost Efficiency
Dramatically reduce infrastructure costs by eliminating idle resource waste and optimizing accelerator utilization.
Why Now
The GPU Utilization Crisis
Organizations are facing a perfect storm: AI workloads are exploding while GPU availability remains constrained and expensive. The default response—over-provisioning to handle peak demand—creates massive waste. Studies show that GPU utilization in typical ML research environments averages 30-50%, meaning billions of dollars in compute capacity sits idle.
Why Static Allocation Fails
Traditional approaches treat GPU allocation like server provisioning: once assigned, a GPU stays locked to a workload until explicitly released. This made sense when GPUs were primarily batch processing engines, but modern AI workflows are interactive and bursty—Jupyter notebooks, agent systems, development environments. These workloads have natural idle periods, but conventional orchestration has no way to reclaim resources during downtime without destroying state.
Existing "Solutions" Create New Problems
Time-sharing and multi-instance GPUs, as well as Kubernetes DRA, help pack more workloads on hardware, but they don't solve idle waste—they just subdivide the problem. Manual scheduling requires developers to babysit jobs and deallocate resources themselves. Forced eviction-based systems lose state and disrupt workflows. Organizations need a solution that eliminates waste without sacrificing developer experience.
The Missing Layer
What's needed is a stateful elasticity layer—infrastructure that can automatically yield resources during idle periods and restore them seamlessly when work resumes. Until recently, this wasn't technically feasible. NVIDIA's CUDA checkpoint API and advances in state management have finally made true activity-aware allocation possible.
Case Studies
We've analyzed public production cluster datasets to put real numbers behind the GPU idle waste problem.
of GPU memory-time wasted
Alibaba Stable Diffusion Serving
143 production pods serving Stable Diffusion held ~26 GB of GPU memory each while sitting at 0% compute for two-thirds of their lifetime. Mean fleet-wide GPU utilization: 7%.
Read case study →of GPU minutes idle, mid-job
Microsoft Philly GPU Cluster
117,325 DNN training jobs show roughly half of GPU time is idle — and 65% of that idleness is mid-job, not trailing time after completion.
Read case study →GPU capacity idle while 861 jobs queue
Alibaba PAI GPU Cluster (2023)
6,212 GPUs, 8,152 jobs. Fragmentation from fractional GPU allocation leaves 46% of cluster capacity unreachable — and 67 TB of GPU memory locked to idle cards.
Read case study →mean GPU compute utilization, fleet-wide
Alibaba PAI GPU Cluster (2020)
3 million instance records across 6,742 GPUs. Mean utilization is 10.5%; 75% of instances average below 10% compute while holding GPU memory — 54% of memory-time wasted.
Read case study →Use Cases
Affinode is currently designed for teams running GPU workloads where interactive patterns create idle time.
ML Research Teams
- Researchers in meetings while holding GPU allocations
- Development environments that alternate between active coding and idle time
AI Platform Teams
- Multi-tenant clusters where users request more GPUs than they actively use
- Internal ML platforms serving dozens of data scientists
- Shared research infrastructure with unpredictable usage patterns
AI Agent & Chat Deployments
- LLM agents waiting for user input or external API responses
- Chatbots with bursty traffic patterns
- Interactive AI applications with high latency between requests
Not (Currently) For
- Continuous batch training jobs that max out GPUs 24/7
- Single-user dedicated GPU workstations
Architecture Overview
How Affinode Works
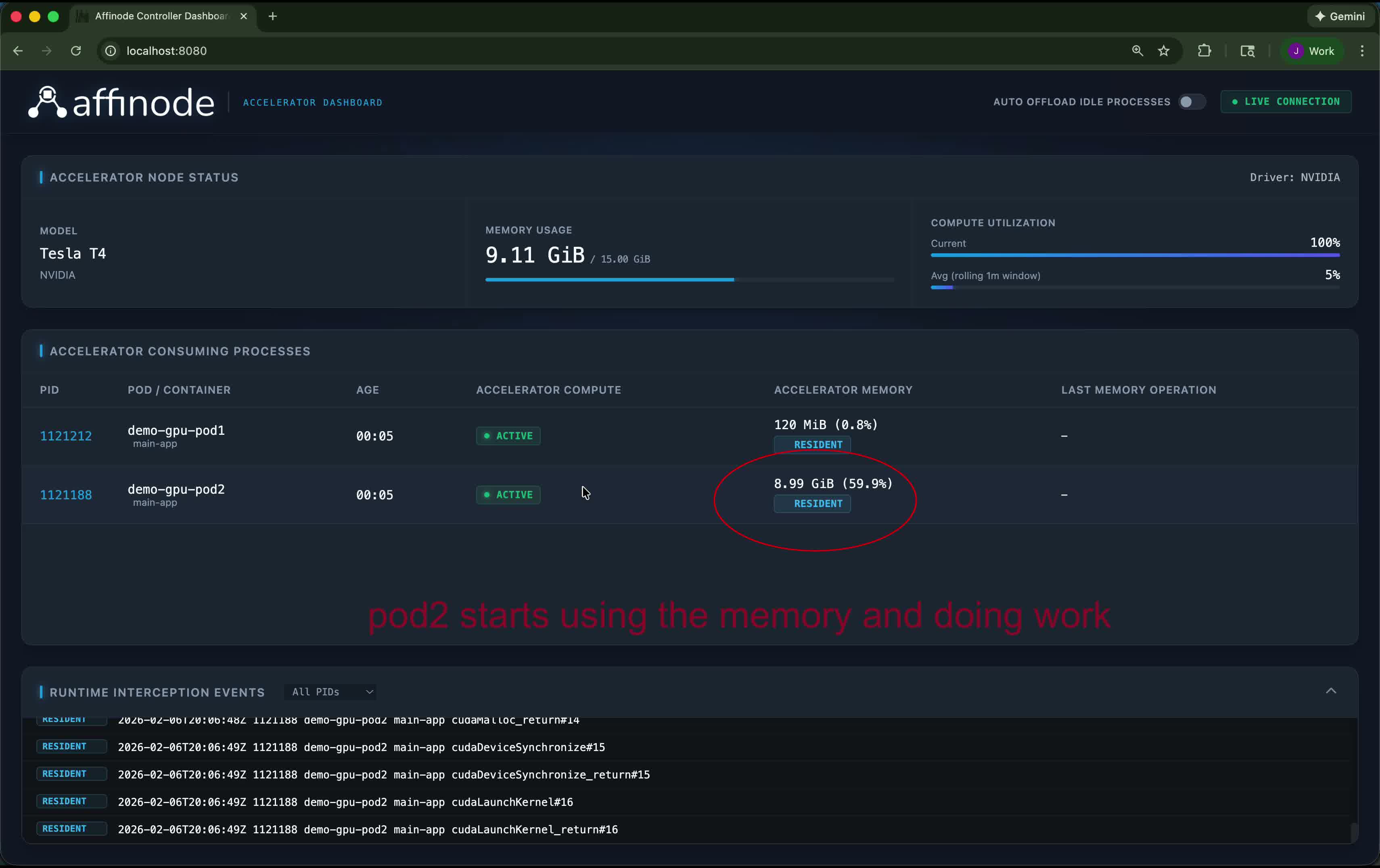
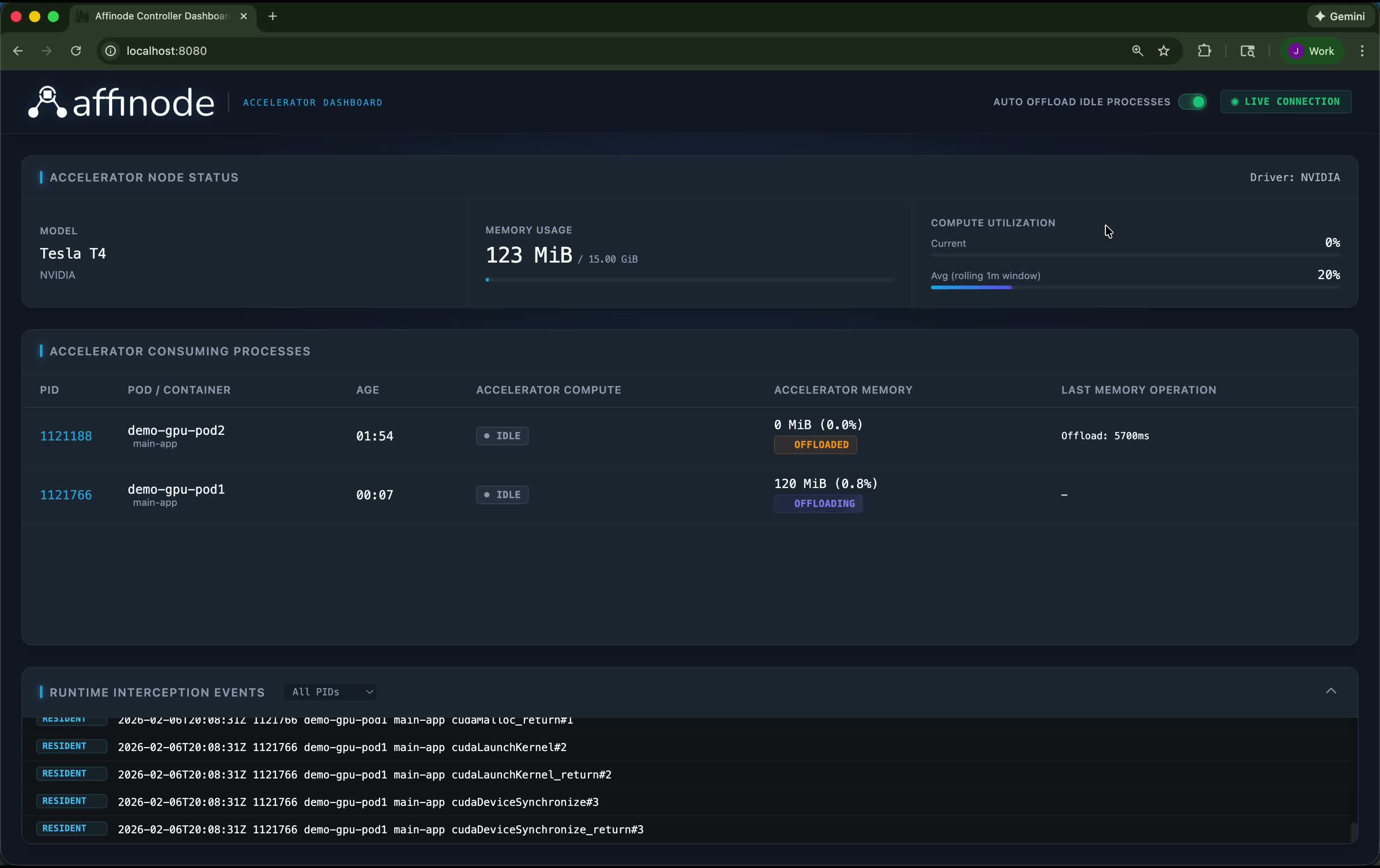
Although core Affinode functionality does not need Kubernetes, it currently is built on top of Kubernetes for ease of deployment (more platforms to support in the future). After you deploy Affinode, a daemonset runs on each GPU node and a mutating webhook intercepts GPU pod creation. The webhook injects a lightweight monitoring binary into each GPU container that transparently tracks CUDA API activity and reports to the node controller.
The controller analyzes CUDA call patterns to detect idle workloads using temporal inactivity, sentinel signals, and memory footprint analysis. When a pod goes idle, Affinode uses NVIDIA's CUDA checkpoint API to offload VRAM contents to the pod's RAM space, freeing GPU memory for other workloads. When activity resumes, the controller detects incoming CUDA calls and restores the checkpoint—your workload continues exactly where it left off with zero state loss.
Policy Engine
Configurable policies control when and how resources are reclaimed. Annotate pods to prevent interruption for latency-sensitive workloads, or leverage priority-aware policies to intelligently choose which idle pods to checkpoint when multiple candidates exist. Support for pod profiling and historical usage patterns is on the roadmap.
Zero-Friction Adoption
No application code changes. No workload evictions. No manual intervention. Affinode adapts to your actual usage patterns and maximizes GPU utilization while preserving the developer experience your teams expect.
See it in Action
Watch how Affinode identifies idle processes and frees up memory footprint, drastically increasing accelerator utilization.
Product Roadmap
Available Now
- Single GPU applications
- Kubernetes integration
- CUDA checkpoint-based state preservation
- Basic idle detection
- Pod-level opt-out controls
Next
- Intercept CUDA driver API calls
- Enhanced policies for offload/restore
- Priority-aware offload/restore
-
Enhanced idle detection
- Process memory footprint
- Historical profiling for smarter idle prediction
- Enhanced open-source observability and utilization dashboards
Future
-
Scheduling loop
- Have a k8s scheduler which takes the idleness observations into account
- Support Slurm and other platforms
- Support Multi-GPU applications
- Predictive restore based on usage patterns
-
Cluster Autoscaling Integration
- Use restore queue depth as a signal to provision additional GPUs
- Consolidate fragmented workloads across under-utilized nodes, enabling scale-down of idle infrastructure
- Cost-aware restore policies (e.g., prioritize restoring to spot instances based on the pattern)
-
Process clean-up
- Detect and clean up processes that can no longer make progress (e.g. gang-scheduling failures)
- Cost attribution and chargeback reporting
- Support for non-CUDA accelerators (AMD, TPUs)
Common Questions
No. Affinode requires zero code changes. You deploy it on your cluster, and it automatically manages your workloads.
Yes. Affinode works at the CUDA level, making it application agnostic and compatible with all frameworks which use NVIDIA GPUs.
When the process is active, the overhead is just the monitoring binary which is lightweight (dynamically linked to the CUDA driver). The initial results of restore times show about 1s per 10GB of VRAM on a VM with PCIe Gen 3 interface (T4), and about 40GB/s on a VM with PCIe Gen 5 interface (H100).
No. All data processing, monitoring, and checkpointing happens locally within your cluster. Your data never leaves your environment. In the future, we plan to collect usage metadata for a central dashboard and idle time statistics.
By default, Affinode will keep the process in the offloaded state and use a FIFO queue to restore processes in order. It will also notify the user about the memory pressure. It's also possible to set a "restore-immediately" policy, in which case it terminates the most recently replaced processes.
Not yet. Affinode currently supports single-GPU pods. If you have multiple single-GPU pods on the same node, Affinode manages each independently. Support for workloads that use multiple GPUs (like distributed training) is on our roadmap.
Affinode uses a lightweight CUDA plugin to intercept CUDA runtime API calls. This plugin is loaded dynamically (LD_PRELOAD) at container initiation and intercepts the most common CUDA runtime API calls made by the application. We have plans to support more CUDA runtime API calls and eventually intercept CUDA driver API calls in the future.
No. Affinode uses NVIDIA's CUDA checkpoint and restore APIs, not CRIU (Checkpoint/Restore In Userspace). The key difference: your process stays alive throughout the checkpoint and restore cycle. We only checkpoint GPU state (VRAM contents, CUDA contexts), not the entire process. This means faster checkpoint/restore times, no process restart overhead, and seamless continuation of CPU work while GPU memory is offloaded.
The process continues running normally and can execute any CPU operations. If the application makes new CUDA API calls while checkpointed (for example, trying to launch a kernel or access GPU memory), those calls are blocked by the CUDA driver. Affinode intercepts these calls and evaluates whether to initiate a restore immediately (if GPU memory is available) or queue the request (if memory is still constrained) to provision a new GPU. Once the restore completes, all pending CUDA operations execute in order, and the application continues as if nothing happened. From the application's perspective, CUDA calls during checkpoint simply experience higher latency.
Most applications work seamlessly, but there are edge cases. Affinode currently intercepts CUDA runtime API calls, which covers the vast majority of GPU workloads (PyTorch, TensorFlow, JAX, etc.). However, applications that directly use the lower-level CUDA driver API, rely on CUDA IPC (inter-process communication), or use certain advanced CUDA features may not be fully supported yet. We're actively expanding coverage, and our roadmap includes driver API interception and multi-process CUDA support. If you have a specific use case, reach out—we can help assess compatibility.
Affinode is complementary to time-sharing and DRA, not a replacement. Time-sharing and DRA subdivide a GPU among multiple pods, but they don't reclaim capacity when pods go idle. An idle pod still occupies its GPU memory slice and holds onto GPU resources like CUDA contexts and streams.
This creates a noisy neighbor problem: even if a pod is sitting idle doing nothing, its memory footprint can cause other pods to OOM. With Affinode, idle processes are fully offloaded—not just GPU memory, but the entire GPU context (CUDA streams, contexts, kernel state). This frees up both memory and GPU resources for active workloads, allowing more pods to collocate on that node and increasing overall GPU utilization.
No. Unified Memory (UVM) handles memory paging within a single application, but it adds significant page fault overhead—typically 1.5-2x slowdown even with optimal prefetching. UVM also doesn't detect idle workloads or coordinate across multiple pods.
Affinode operates at the orchestration level. It detects when entire pods are idle, checkpoints their full GPU state (not just memory), and frees that capacity for other workloads. UVM optimizes single applications; Affinode optimizes multi-tenant clusters.
The Team

Javad Taheri
Founder
Javad is a systems engineer specializing in cloud infrastructure and Kubernetes. At Google Cloud he worked on GKE, contributing to GKE's resource-management and scheduling systems, with a primary focus on Autopilot. Working directly on GPU utilization challenges and hearing from customers struggling with idle waste, the idea for Affinode took shape. Before Google, across two infrastructure startups he built deep Kubernetes expertise designing and operating multi-tenant platforms. Earlier at Microsoft he worked on cloud infrastructure for Dynamics CRM, gaining hands-on experience running large-scale enterprise services.
LinkedIn ProfilePreviously
Let's Solve This Together
We're working with early customers to tackle GPU idle waste in production clusters. If you're experiencing low GPU utilization, fighting for scarce resources, or burning budget on idle capacity, we want to hear from you.
Affinode is in active development—this is your chance to shape the product and get early access. Whether you want to run a proof-of-concept, discuss your specific challenges, or just compare notes on GPU infrastructure, reach out to us.